
Birkaç yıl önce ışın izlemeyi daha iyi anlayabilmek için Ray Tracing in One Weekend kitabını okudum. Orijinal kod örnekleri C++ ve ben okudukça Python’a çevirip yazıyordum. Evet, korkunç bir fikir olduğunu baştan biliyordum; ama merak. Python’un performans açısından yetersizliğini en iyi gözlemleyebileceğiniz yöntemlerden biri, ışın izleme algoritmasını, genişliği 1000 pixel olan resim üreterek test etmektir. Fakat 300 pixel bile epey zaman alıyor. Dolayısıyla ya interoperability, ya multiprocessing, ya da GPU kullanımı gibi alternatif çözümlere başvuruyorsunuz. Bu da ışın izlemeyi öğrenirken beraberinde çözmem gereken eğlenceli ve ekstra bir iş olarak karşıma çıktı.
Kod GitHub reposunda, indirip terminalden kullanabilirsiniz. Aynı zamanda Hugging Face Spaces üzerinden deneyebilirsiniz; ancak GPU’yu aktif etmek için repoyu forklayıp GPU’nun olduğu bir sunucuda çalıştırmanız gerekiyor. Benim bu çalışmayla ilgili paylaşmak istediğim birkaç konu var:
- Dünyanın en popüler dillerinden biri olan Python neden yavaş?
- Hugging Face sunucusunda Rust kodu çalıştırabilmek, cross-compilation.
- CUDA’yı anlamak, GPU’yu backend projelerinde kullanmak.
- Buradaki bilgileri bir şablon olarak göz önünde bulundurmak.
Python Neden Yavaş?
Aslında cevabı basit: Python yorumlamalı (interpreted) bir dil. Makineyle dil arasında bir yorumlayıcı var ve dil odaklı yapabileceğin optimizasyonlar limitli. Örneğin yorumlayıcının en büyük getirisi olan GIL (Global Interpreter Lock), C/C++ gibi dillerde manual olarak yapılan birçok işi otomatik yaparak hem kodun okunurluğunu sağlayıp hem de esas işe odaklanmanıza yardımcı olurken, diğer taraftan CPU’nun tüm performansından yararlanmanıza engel olur. Işın izlemede pixel sayısı arttıkça, for döngüleri artıyor ve her döngüde nesnelerin oluşturulması, algoritmanın çalışması, hafızanın temizlenmesi gibi maliyetler katlanarak artıyor. Bir de çoğu Python programcısının sıkça duyduğu şey var: “Python’da neredeyse her şey bir objedir.”. Yani C++‘ta bulunan temel veri tipleri ile Python’daki int, string aslında birebir aynı şeyler değiller.
Peki performans konusu Python’da bu kadar umutsuz vaka mı? Tamamen ne beklediğimize ve ne ile tatmin olabileceğimize bağlı. Bir kere ışın izleme için CPython yorumlayıcısını kullanmanın kötü bir tercih olduğunu baştan kabul etmek lazım. Ama dediğim gibi biz ürün odaklı bir şey yapmak yerine merak gidermek ve ileride benzer bir şeye muhtaç kaldığımızda neler yapabildiğimizi görmek istiyoruz.
İlkiyle başlayalım, diller arası birlikte çalışabilirlik.
Python - Rust Birlikte Çalıştırabilirlik
Biliyorum, ilk akla gelen çözüm aslında multiprocessing olmalıydı. Ama Peter Shirley’in C++ kodunda da bununla ilgili herhangi bir şey yok, zaten gerek de yok. RAYT ilk yazmaya başladığımda pure Python’du, tek CPU çekirdeği ile ve korkunç derecede yavaş çalışıyordu. Multiprocessing’in beklediğim iyileştirmeyi vereceğinden emin değildim; ama interoperability’nin mutlak bir katkısı olacağından emindim. Tek sıkıntı, Python dışında seçeceğimiz yardımcı dili öğrenmemiz gerekiyor.
Peki küçük bir soru: Madem başka bir dilden destek alacağız, neden sadece o dilde yazmıyoruz? Motivasyonumu ara sıra hatırlatmama izin verin. Benim amacım, ışın izleme yazmak değil. O onlarca dilde, farklı geliştiriciler tarafından defalarca yazıldı zaten. Benim amacım, çalıştığım herhangi bir Python projesinde bir performans problemini çözmek zorunda kaldığımda neler yapabilirimin cevaplarını aramak.
İlk önce, hazırda C++ kodu varken pybind11 ile Python’da çalıştırılabilir hale getirmeyi düşündüm. Ama sonra paketlemede, bağımlılıkların yüklenmesinde, cross-compilation yapabilmek için Rust’ta daha az efor sarfedeceğimi düşündüm.
Bu arada Python’un paket yöneticilerinin ne kadar başarısız olduklarını hep başkaları kullanırken fark ediyorum. Conda içinde pip kullanmalar, pyenv ile poetry kullanmalar, pyproject.toml dosyasına sahip olup paketleri yüklemek için requirements.txt kullanmalar. Tam bir kaos; ama suç paket yöneticilerinde. Her neyse, bu konuya girmeyeceğim, şu anda daha iyisi gelene kadar uv bana göre en iyisi ve Rust interoperability desteği çok iyi, ne de olsa kendisi de Rust ile yazılmış bir Python aracı:
uv init --build-backend maturin rayt-rust
Bu sihirli komut, Rust kodunu Python’da kullanabilmeniz için gerekli dosyaları ve dizin yapısını sizin için oluşturuyor:
rayt-rust
└── src
└── lib.rs
└── rayt_rust
└── __init__.py
└── _core.pyi
└── README.md
└── Cargo.toml
└── pyproject.toml
2 directories, 6 files
Rust kodu src/ dizininde olacak, bağımlılıklar Cargo.toml dosyasına yazılacak. Kabaca bu kadar, uv build komutunu çalıştırdığımızda rayt_rust paketi Python’da kullanıma hazır hale gelecek. Fakat bir sorun var, yine motivasyonumuza geri dönecek olursak, bizim amacımız bütün kodu Rust ile yazmak değil; sadece performans açısından kritik olan kısmı Rust’a taşıyıp, geri kalanı Python’da tutmak. Bunun da iki yolu var:
- Performans kritik kısımlar için ayrı bir kütüphane hazırlayıp, Python projesine bağımlılık olarak kurmak.
- Tüm modülleri tek bir paket içinde barındırmak.
Ben RAYT için ikincisini seçtim. src/ dizininde rayt/ ve rayt_rust/ adında iki farklı dizinin olmasının sebebi budur. Böylece uv run one-weekend komutunu çalıştırdığımda, Rust kodu otomatik olarak build edilmiş ve kullanıma hazır hale geliyor.
Ancak birinci seçeneğin örneğini de Hugging Face sayfasında göstereceğim.
RAYT’i Hugging Face Spaces’te Kullanmak
Gradio, ML modelleri için web arayüzü hazırlamanızı sağlayan basit ve kullanışlı bir Python kütüphanesidir. Hugging Face Spaces ise Gradio’yu çalıştırabileceğiniz, GPU desteği olan, benzer pratiklikte bir servis. Şimdi GPU kısmını bir kenara bırakalım ve basit bir web arayüzü ile RAYT’ı çalıştıralım. Gradio ile yapılmış web uygulamasını buradan deneyebilir, kaynak kodlarını inceleyebilirsiniz, dikkatinizi ilk çekmek istediğim şey requirements.txt dosyası:
gradio
numba-cuda[cu13]
https://huggingface.co/spaces/goedev/rayt-web/resolve/main/rayt-0.1.0-cp310-abi3-manylinux_2_34_x86_64.whl
Hem yerelde, hem HF Spaces’te çalışabilmesi için gerekli tüm bağımlılıkları yazdım. RAYT bir link olmak zorunda, çünkü sanırım deployment sırasında HF Spaces requirements.txt dosyasını farklı bir dizine kopyalıyor ve .whl dosyasını bulamıyor. Repo dışarıya açık olduğu için ilk aklıma gelen çözüm bu oldu, bir diğer çözüm kendi Dockerfile dosyanızı hazırlamak.
İkinci sorun, RAYT artık derlenebilen bir kitaplık olduğu için, hangi Python sürümünü kullandığınıza, hangi işletim sistemi için derleyeceğinize dikkat etmeniz gerek. HF Spaces varsayılan olarak Python 3.10 ve Linux kullandığı için ona göre geliştirme ortamı hazırlamanız gerekiyor. Normalde yerelde RAYT’ı test etmek için rustup (Rust ve cross-compilation için) ve uv (Python için) kurmanız, sonrasında bu adımları takip etmeniz yeterli:
gh repo clone gkmngrgn/rayt && cd rayt
uv build
Yanlış bilmiyorsam rustup, ilk kurulduğunda gerekli olan target‘i, kullandığınız platforma göre yüklüyor. Yerelde RAYT CLI kullanmak istediğinizde sorun yok; HF Spaces için özel bir build almanız gerekiyor. Interoperability için Rust seçmemin bir nedeni de bu, C++ kodunu WASM’de çalıştırmak için attığım taklaları düşününce, Maturin’in sağladığı konforun daha iyi farkına varıyorum. Şimdi doğru target’i yükleyip, build etmeyi deneyelim:
rustup target add x86_64-unknown-linux-gnu
uv tool install maturin
uvx maturin build --target x86_64-unknown-linux-gnu
ls target/wheels/
rayt-0.1.0-cp310-abi3-manylinux_2_34_x86_64.whl
Güzel, Python distrosu CPython, versiyon 3.10, işletim sistem Linux, işlemci mimarisi x86_64. Alles gut. Şimdi bunu web uygulamamızda kullanabiliriz. Bu basit bir şablon proje olduğu için olabildiğince kompleksiteden kaçınıyorum. Her projenin ihtiyaçları, tercih edilen araçlar farklı farklı olduğu için. Normalde bu iş, DevOps sürecinin bir parçası olmalı; yeni sürüm çıktığında build işlemi CI/CD sunucularında başlamalı, artifactlar CodeArtifact gibi bir servise yüklenmeli, web projeleri paketleri bu servisten kurabilmeli vesaire. Repo ile ilgili ikinci dikkat çekmek istediğim şey .gitattributes dosyaya bakalım:
*.parquet filter=lfs diff=lfs merge=lfs -text
*.pb filter=lfs diff=lfs merge=lfs -text
*.pickle filter=lfs diff=lfs merge=lfs -text
*.pkl filter=lfs diff=lfs merge=lfs -text
*.pt filter=lfs diff=lfs merge=lfs -text
*.pth filter=lfs diff=lfs merge=lfs -text
*.rar filter=lfs diff=lfs merge=lfs -text
*.safetensors filter=lfs diff=lfs merge=lfs -text
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.tar.* filter=lfs diff=lfs merge=lfs -text
*.tar filter=lfs diff=lfs merge=lfs -text
*.tflite filter=lfs diff=lfs merge=lfs -text
*.tgz filter=lfs diff=lfs merge=lfs -text
*.wasm filter=lfs diff=lfs merge=lfs -text
*.xz filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
*.whl filter=lfs diff=lfs merge=lfs -text
Büyük dosyaları repoda tutmak iyi bir fikir değil. Örnek vermek gerekirse, bazen projelerde çalışmak için bu dosyalara ihtiyaç yoktur, bu dosyaların boyutu arttıkça repoyu clonelamak gereksiz zaman alır. Git LFS, Xet, DVC, bu sorunu çözmek için kullanılan araçlardan bazıları. 304 kb’lik bir pakette bu çok büyük bir problem olmayabilir ama şirket projelerinde önlemi baştan almanızda yarar var. Peki .gitattributes nasıl oluşturuluyor? Öncelikle git-lfs yüklemeniz gerekiyor:
git lfs install
git lfs track *.whl
git add .gitattributes
Bundan böyle *.whl dosyası commitleyip pushladığınızda, LFS bu dosyayı ayrı bir storage’de tutacak. Bir web projesinde, Rust ile yazılmış Python kitaplığını nasıl kullanacağımızı artık biliyoruz.
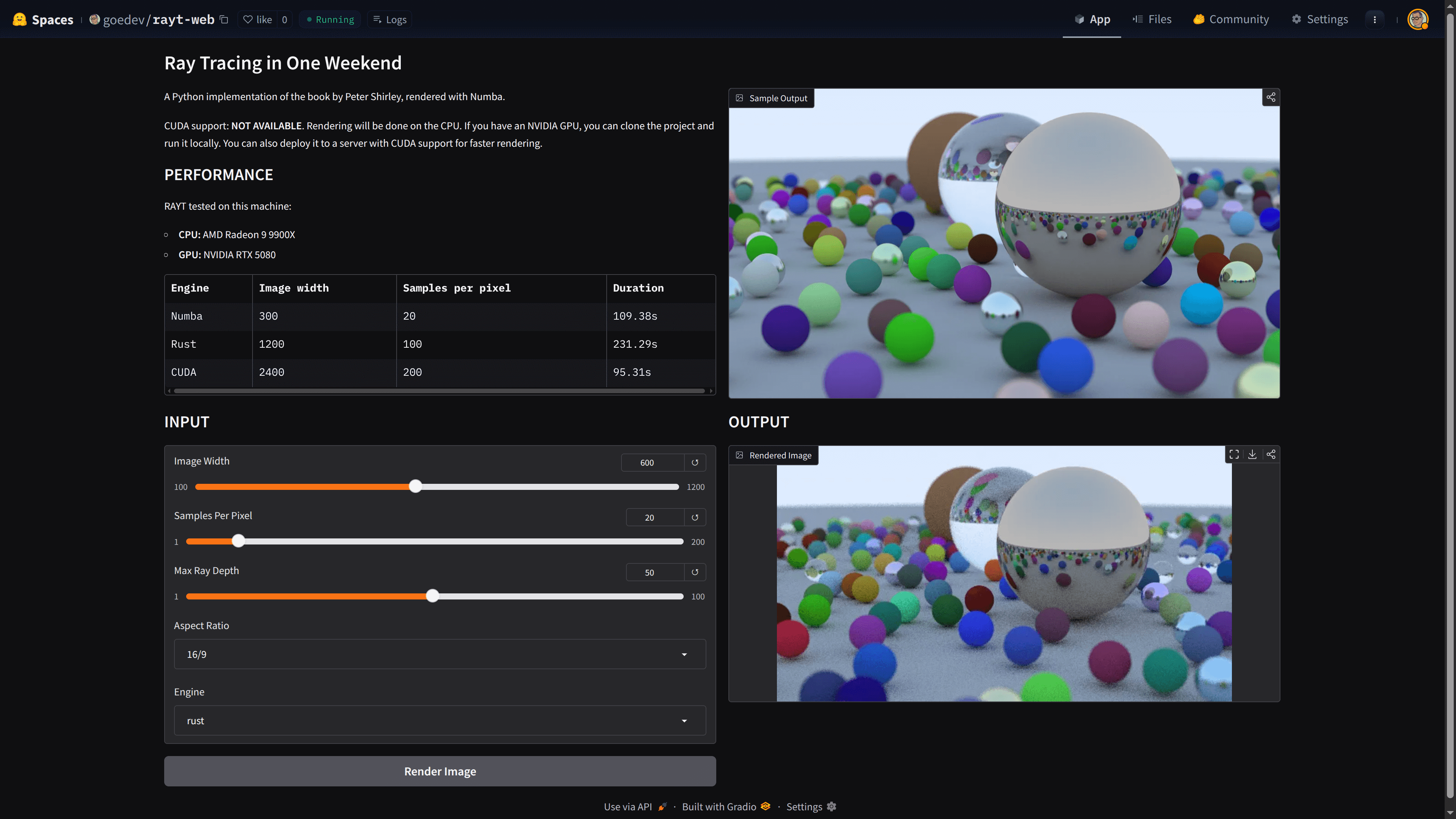
Rust, RAYT’ın Performans Problemini Çözdü mü?
Bir C++ kadar hızlı değil, hatta tamamen Rust ile yazılmış bir CLI kadar bile hızlı değil muhtemelen. Ama, Python’dan katbekat hızlı. Performans problemini büyük ölçüde çözdü diyebiliriz; peki ya bir GPU kullanmak istersek? Hem Rust interoperability, hem Rust üzerinden GPU’ya erişim?? Yok bekle, o kadar değil, o kadar vaktim yok. Ama muhtemelen onu da yapmak mümkün, sunucuda CUDA destekli bir GPU varsa, neden olmasın?
Ama Rust’i şimdilik bir kenara bırakalım ve başka bir konuya odaklanalım. Python kodu yazarak, CPython kullanarak, GPU’nun gücünden yararlanabilir miyiz? Bunu yapmanın eminim birden fazla yolu vardır; ben Numba ile denedim.
Numba ve Numba CUDA
Numba, LLVM derleyici kütüphanesini kullanarak Python kodunu runtime aşamasında optimize edilmiş makine koduna çevirip CPU’da çalıştırılmasını sağlayan (başka nerede çalışacak?) bir Just-In-Time (JIT) derleyicidir.
Numba CUDA, Python kodunu PTX koduna (Parallel Thread Execution) çevirip CUDA GPU çekirdeklerinde çalışmasını sağlayan bir ek pakettir.
CUDA (Compute Unified Device Architecture), bizim NVIDIA’nın grafik işlem birimlerinin (GPU) muazzam işlem gücünü, GPGPU olarak bilinen genel amaçlı hesaplamalar için kullanmamıza olanak tanıyan bir platformdur.
Özetle, Numba’yı bir JIT Compiler, CUDA’yı bir target olarak düşünebilirsiniz. RAYT’ı Rust ile yeniden yazmamızdaki aynı temel motivasyonu içerir. Fakat Numba CUDA kullanmak için başka bir programlama dili öğrenmeye ihtiyacınız yok, sadece CUDA mimarisinin nasıl çalıştığını bilmemiz gerekiyor, onun dışında GPU memory allocation/deallocation için bile hiçbir şey yapmanıza gerek yok. Fakat Numba CUDA’nın iki dezavantajı var:
- JIT compilerların ilk çalıştırmada kod çeviri ve derleme için bir bekleme süresi olur. Toplam süreyi düşündüğünüzde gözardı edilebilir bir süre.
- Tahmin edebileceğiniz gibi grafik ekran kartına, ekran kartını kullanabilmek için driverlara ve CUDA’yı kullanabilmek için ek paketlere ihtiyacınız var.
Şimdi tekrar RAYT koduna geri dönelim ve Rust dışında diğer seçenekleri gözden geçirelim. Kod tekrarlarını biraz önlemek için, kritik olduğunu düşündüğüm bazı fonksiyonları Numba’ya taşıyıp, geri kalan kısmı için Rust kodunu kullanmaya devam ettim, ama farz edin bunda Rust kodu hiç yok ve sadece Numba kullandık, gerçek bir projede ikisine birden ihtiyaç olacağını pek sanmıyorum.
Her ne kadar sadece Python kodu yazıyor olsak da, bazı kısıtlar mevcut:
try - exceptkullanamıyoruz.- Context management (
with) yok. - Generator yok.
- list, dict, set ile yapılan comprehensionlar yok.
- Debugging biraz sandığımızdan farklı yapılıyor.
- En kötüsü, typing desteği kısıtlı ve biraz alışılmışın dışında.
Ama NumPy kullanabiliyoruz ve bunun önemini şöyle anlatayım: Siz CPython kullanacaksınız, sizin belli veri tiplerinde Python’da tanımladığınız değerleriniz olacak ve bunları NumPy arraylarına dönüştürerek Numba fonksiyonlarına parametre olarak iletebileceksiniz. Aynı şekilde, bu fonksiyonların döndürdüğü değerleri yine NumPy array olarak geri alabilecek veya fonksiyonlar arasında birbirlerine gönderebileceksiniz. Bunu nasıl yaptığımı anlayabilmek için en güzel örnek _prepare_scene_data metodu:
import numpy as np
import numpy.typing as npt
from rayt_rust._core import Camera, HittableList, get_color, Color
from rayt.numba_optimized import render_pixel_numba
class NumbaRenderer:
"""Numba-optimized ray tracer renderer"""
def __init__(self) -> None:
self.spheres_data: npt.NDArray[np.float64] | None = None
self.materials_data: npt.NDArray[np.float64] | None = None
self.camera_data: npt.NDArray[np.float64] | None = None
def _prepare_scene_data(self, world: HittableList, camera: Camera) -> None:
"""Convert scene objects to NumPy arrays for Numba"""
# Sphere data: [center_x, center_y, center_z, radius]
self.spheres_data = np.array(world.get_sphere_data(), dtype=np.float64)
# Material data: [type, param1, param2, param3, param4]
# Type 0: Lambertian [type, albedo_r, albedo_g, albedo_b, unused]
# Type 1: Metal [type, albedo_r, albedo_g, albedo_b, fuzz]
# Type 2: Dielectric [type, ref_idx, unused, unused, unused]
# Default to Lambertian with white color
self.materials_data = np.array(world.get_material_data(), dtype=np.float64)
# Camera data: [origin, lower_left_corner, horizontal, vertical, lens_radius, u, v]
self.camera_data = np.array(camera.get_data(), dtype=np.float64)
...
Bunu test etmek için Rust’taki bazı performans kritik kodları JIT compiler’a taşıyarak başladım. Web projemizde Engine olarak numba seçerek deneyebilirsiniz. Denemeden önce sizce Rust’a göre performansı nasıl olmuştur, bir düşünün. İpucu aynı sayfada var. İkisinde de CPU kullanıyoruz.
Benim izlenimim, üzerinde çalıştığımız projenin gereksinimlerini gerçekten çok iyi anlamamız ve iki seçeneğin avantajları ve dezavantajlarını subjektif bir şekilde ortaya koyarak, maliyeti doğru hesaplamamız gerekiyor. Numba da pure Python’a göre performans açısından bir katkı sağlıyor; ama Rust kadar değil. Daha fazlasına ihtiyacımız var mı, onu yapabilecek bilgi birikimimiz, zamanımız, kapasitemiz var mı? Hepsi göz önünde bulundurulmalı.
Numba’da bence esas olay CUDA ile başlıyor. Numba kodunu CUDA ile çalışabilir hale getirirken ilk öğrenmem gereken konu Thread Hierarchy oldu.
Kernel ve Thread Hierarchy
CUDA’nın özünde başardığı en önemli şey, biz programcılara binlerce çekirdeğin tekrarlayan işleri eş zamanlı olarak başlatma imkanı vermesidir, yani paralel processing. Bu işlem kabaca şöyle gerçekleşir:
- Verinin RAM’dan VRAM’e taşınması. VRAM, grafik işlemci biriminin kullandığı video random-access memory. Veri ilk önce buraya taşınmak zorunda çünkü işlemi GPU’ya yaptıracağız.
- GPU’da kernel adı verilen hesaplamanın çalıştırılması. Bu talimati biz CPU’ya veriyoruz, CPU da Numba CUDA sayesinde GPU’ya iletiyor. GPU eş zamanlı olarak VRAM’deki veriyi veya bütün çekirdeklerini paralel olarak kullanarak hesaplamayı yapar.
- Hesaplanan verinin VRAM’den RAM’e geri taşınması. Biz host olarak CPU kullanıyoruz ve iletişimimizi hep CPU üzerinden yaptığımız için bu aşamaya da ihtiyaç duyuyoruz.
Biz python run main.py dediğimizde, CPU’ya bu programı çalıştırması için talimat vermiş oluyoruz. Fakat bir hesaplamanın GPU’da çalıştırılmasını istediğimizde bizim kernel adını verdiğimiz özel fonksiyonlar tanımlamamız gerekiyor. RAYT’teki kernel fonksiyonu çok uzun ama burada kırparak birkaç noktaya değinmek istiyorum:
@cuda.jit
def render_pixels_cuda(image_width, image_height, samples_per_pixel, ...):
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
if i >= image_width or j >= image_height:
return
...
# Store result (note: j is flipped for correct image orientation)
output[image_height - 1 - j, i, 0] = pixel_color[0]
output[image_height - 1 - j, i, 1] = pixel_color[1]
output[image_height - 1 - j, i, 2] = pixel_color[2]
@cuda.jit dekoratoru, render_pixels_cuda kernel fonksiyonumuzun native GPU koduna (PTX) dönüşmesini sağlar. Daha sonra bu fonksiyonu grid ve block size parametreleri üzerinden çalıştırıyoruz:
# Calculate optimal block and grid sizes
block_size = 16
grid_size = (
(image_width + block_size - 1) // block_size, # Point.x
(image_height + block_size - 1) // block_size, # Point.y
)
render_pixels_cuda[grid_size, block_size](image_width, image_height, samples_per_pixel, ...)
Grid ve Block size nedir? Bunu anlamak için tek thread ve CPU üzerinden programlama yaptığımızı düşünelim. Normalde oluşturmak istediğimiz imajın her bir pixeli için ışın rengini hesaplamamız gerekiyor:
for j in range(image_height, 0, -1):
for i in range(image_width):
...
İç içe iki for döngüsü aslında bize bir ızgara oluşturuyor. Fakat problem şu: Bu ızgaradaki bir noktada renk hesaplaması bitmeden ikincisine geçemiyor, her şey sıralı ilerliyor. GPU’da ise, daha kernel fonksiyonunu çalıştırmadan, elde etmek istediğimiz imajın genişlik ve uzunluğu ile orantılı bir ızgaraya sahibiz. Yani GPU, kernel fonksiyonunu çalıştırdığında ışın hesaplaması resmin her noktasında aynı anda başlamaya hazır olacak.
Sanırım ızgara boyutu konusu anlaşıldı, aklınızda oluşturmak istediğiniz bir imaj canlandırın ve bu imajın her bir noktası ile bir block ilgileniyor. Bir de her bir block için ayıracağınız thread var, o da ikinci parametre block_size ile tanımlanıyor. Bu thread’i CPU thread ile karıştırmayın, oldukça farklı bir mantıkta çalışıyor. Bir block içindeki threadler, ızgaranın bir noktası ile ilgili talimati, veri kümeleri bölüştürülerek, birbirleriyle eş zamanlı bir şekilde yerine getiriyorlar. Şimdi CUDA’da i ve j‘yi tanımlamak için neden bir for döngüsüne ihtiyacımız olmadığı net, öyle değil mi?
i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
Aslında bu bilgi, en başta sorduğumuz “Python neden yavaş?” sorusu ile ilgili önemli bir ipucu barındırıyor. 640x480 pixel boyutunda küçücük bir resim hesaplatmak için bile 307200 kere renk hesaplamasını tek tek yaptırmaya çalışıyoruz. GPU ise bu ızgara yapısı, ızgarada bulunan her bir blok ve her bir blok içindeki threadlar, toplamda yüzbinlerce thread sayesinde bizi bu darboğazdan kurtarıyor. İşte bu yapıya Thread Hierarchy deniyor.
Peki Hugging Face’de CUDA Kullanmak, Mümkün mü?
Teorik olarak, mümkün. Pratik olarak? Denemedim; ama mümkün olacağını düşünüyorum. RAYT web arayüzünde engine olarak cuda seçip deneyebilirsiniz; ama önce onu GPU olan bir sunucuya deploy etmeniz gerekiyor.
Bir de GPU ile uyumlu CUDA toolkit ve numba-cuda paketlerini kurarsak, çalışmaması için bir neden göremiyorum. Bir NVIDIA ekran kartınız varsa repoyu klonlayıp yerelinizde deneyebilirsiniz, farklı engine’lar ile sonuçları karşılaştırabilirsiniz.
Son Söz
Sosyal medyada bir tartışma vardı, dünyanın en yavaş dili (mi?) olmasına karşın en popüler dili Python ise, performans önemli midir, değil midir üzerine. Bir kere Machine Learning, NLP işlerinde GPU kullanımının artması zaten hızın önemini anlatıyor, buna ek olarak maliyeti de göz önünde bulundurmak gerekiyor. Hız, performans bana göre her zaman önemli olacak, ister GPU ve CUDA programming ile, ister Rust/C++ interoperability ile, ister Python subinterpreterlar veya free-threading kullanarak.
Öte yandan, gelişmeler çok hızlı ilerliyor ve kimsenin öğrenmesi, kodlaması, derlemesi, okuması zor dillerle kaybedecek vakti yok. Python’un popülerliği bundan.